

The Resonance Action Loop
A practical decision framework that connects prioritisation, action and outcome


Abstract
Product teams rarely fail because they lack ideas, talent or data. They fail because decisions about what to do next remain implicit, reversible or disconnected from real-world effects. Backlogs grow, priorities shift and outcomes are discussed long after decisions have already lost their meaning.
The Resonance Action Loop is a lightweight decision framework designed to address this gap. It helps teams decide how to act (not just what to prioritise) by explicitly linking evaluation, action and outcome. Instead of ranking work items, the framework forces a clear choice between learning, delivering or consciously not acting and makes every delivery decision accountable to an observable effect.
The result is not better prioritisation scores, but better decisions under real constraints.
The real problem with prioritisation
Most prioritisation methods focus on a deceptively simple question: What is more important? In practice, this leads to ranked backlogs, endless reordering and implicit commitments that nobody remembers making. Teams appear busy, yet struggle to explain why certain things were built or whether they made a difference.
What is missing is not analytical rigour, but decision clarity. Many product organisations confuse prioritisation with decision-making. Priorities are discussed, but actions are left vague. Learning happens accidentally. “No” is avoided. Outcomes are reviewed too late, if at all.
The Resonance Action Loop reframes the problem by asking a different question:
How will we act on this now and how will we know whether it worked?
This shift (from importance to action) is the foundation of the framework.
What The Resonance Action Loop is (and is not)
The Resonance Action Loop is a decision framework, not a scoring model. It does not calculate value, optimise portfolios or replace strategy. Instead, it structures judgment at the moment where teams usually struggle most: deciding what to do next under uncertainty and limited capacity.
The framework is intentionally lightweight (lightweight in structure, strict in consequences). It works in agile and non-agile environments, requires no tools and fits into existing planning and refinement rituals. At the same time, it is deliberately strict about outcomes: every meaningful decision must result in a clear action and, where appropriate, an explicit way to observe its effect.
What the framework does not do is generate ideas, define vision or remove organisational politics. It assumes that teams have real decision authority. Where that authority does not exist, the framework will expose the problem rather than hide it.
This article explains the framework and its underlying logic. For hands-on application and facilitation, complementary materials are available, including a training slide deck, a workshop guide and an evolving example library.
When the loop should be used
The Resonance Action Loop is not meant to be applied to every small decision. It is most effective when something is genuinely at stake. Teams should use the loop whenever an item competes for meaningful capacity, when there is disagreement about priority, when the expected effect is unclear or when saying “no” feels uncomfortable. These are precisely the situations where informal judgment tends to break down.
For routine, low-impact decisions, the framework can and should be skipped.
Decision authority as a prerequisite
Every application of the Resonance Action Loop requires a Decision Owner. This role is not about facilitation or consensus, but about accountability. The Decision Owner listens to the discussion, weighs the trade-offs and makes the final call once the evaluation is complete.

Disagreement is encouraged before the decision. After the decision, the call stands. Without this clarity, learning turns into delay, delivery becomes implicit and “no” becomes political. In practice, many failed prioritisation processes can be traced back to the absence of clear decision ownership.
The core idea: separating evaluation from action
The framework is built on a simple but often neglected insight: product decisions differ less by their abstract “value” than by the kind of effect they are meant to create and by how ready the organisation is to act on them.
For this reason, the Resonance Action Loop separates evaluation from action. Evaluation is about understanding what an item could achieve and how confident the team is about that assessment. Action is about deciding what to do next, given that understanding. Conflating the two leads to endless debate, separating them creates clarity.
Evaluating decisions through four shared questions
Every item (whether a feature, improvement, technical task or experiment) is evaluated using the same four questions, always in the same order.
First, the team clarifies the Intended Effect. Each decision must have one primary effect: improving Reliability by avoiding disappointment, creating Usage Lift by changing behaviour or adoption, strengthening Positioning by signalling what the product stands for or achieving Load Reduction by reducing friction for users or the team. If the team cannot agree on a single intended effect, the item is not ready for decision and should be parked.
Next, the team assesses Pull Strength by asking how painful it would be not to act. For user-facing work, this may be driven by unmet expectations or visible friction. For internal or technical work, pull reflects accumulated risk, inefficiency or cost of delay. Pull is about felt pressure, not certainty.
The third dimension is Evidence Level. This describes how well the assumed effect is supported: whether it is merely an assumption, plausibly observed or proven through data or real behaviour. Evidence level is not confidence or conviction, it is a statement about the strength of the underlying basis for the decision.
Finally, the team estimates Delivery Cost, including effort, risk and dependencies. Engineering input comes first and teams anchor their estimates around a shared understanding of what constitutes a “typical” delivery. Once delivery cost is discussed, the evaluation is considered locked (locked for this decision cycle, not forever) to prevent endless backtracking.
Examples:
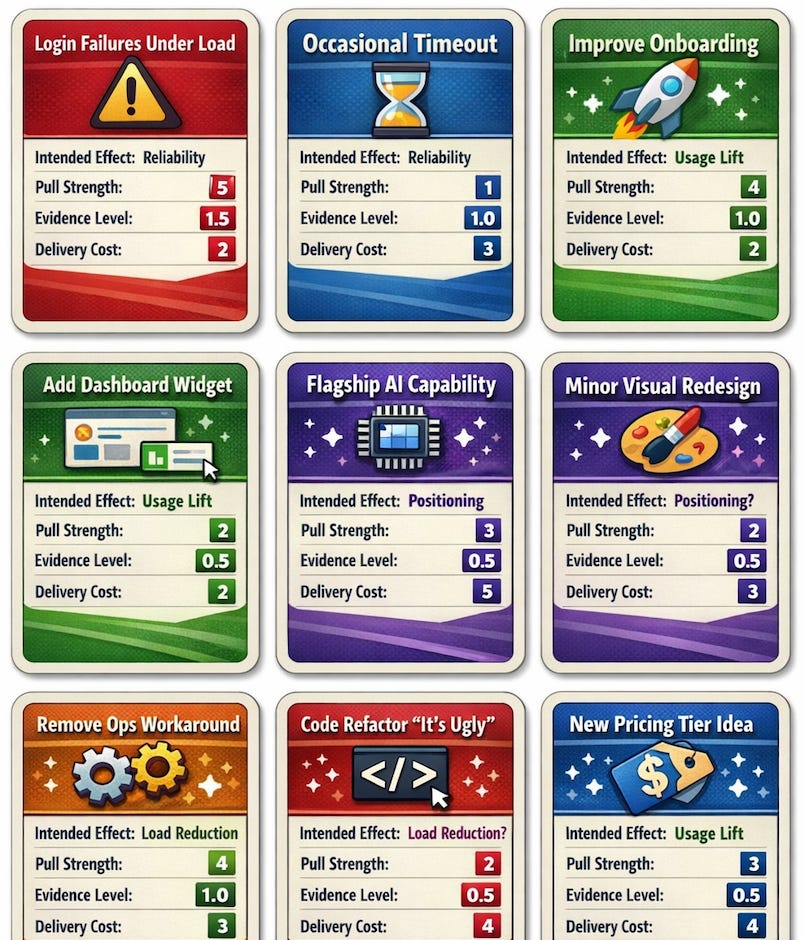
You can find the decision resulting from the evaluation in the Example Library (in the download area at the end of the article).
From evaluation to action: the decisive moment
After evaluation, the team must make an explicit choice about action. The Resonance Action Loop allows exactly three outcomes: Learn, Deliver or Explicit No. There is no “later” and no “maybe”. Choosing an action is the decision.

This is where the framework differs most clearly from traditional prioritisation approaches.
Learning as a first-class decision
Choosing Learn means investing deliberately in reducing uncertainty rather than in producing output. Learning is the default when evidence is weak (unless the Decision Owner explicitly accepts the risk), when the effect is promising but unclear or when delivery cost is high relative to certainty.
To prevent learning from becoming a parking lot, every Learn decision must define a clear learning question, the smallest possible test, the kind of evidence sought and a concrete decision date. Learning always ends in a new decision. If learning does not increase evidence or pull, the default next step is to consciously stop pursuing the item.
This makes learning accountable without making it defensive.
Delivery as a commitment to effect
Choosing Deliver means committing to creating a specific effect. Delivery is appropriate when evidence is sufficient or when uncertainty is explicitly accepted by the Decision Owner.
Every delivery decision must define an Outcome Check. This consists of a simple expected outcome statement, a signal to observe and a time window for observation. The goal is not to set targets or prove success, but to establish a clear link between decision and observable reality.
After the observation window, the team reviews what happened. If the signal moved as expected, the decision is complete (operationally complete, not theoretically settled). If the signal is unclear or negative, the next step is either learning or stopping. Outcome signals indicate correlation, not proof. When causality is uncertain, learning is the appropriate response.
Delivery does not close the loop. Observation does.
Explicit No as a deliberate outcome
Choosing Explicit No means consciously deciding not to act. This decision always comes with a reason: not now, not worth it or wrong effect. Each reason includes a clear re-entry rule, ensuring that “no” is firm without being dogmatic.
By formalising “no” as an outcome, the framework reduces repeated debates, hidden commitments and political re-litigation.
Focus, trade-offs and political reality
To maintain coherence over time, teams define a Decision Focus at the start of a planning period. This focus guides capacity allocation without becoming a rigid goal. Most committed capacity should align with it, but exceptions are allowed when explicitly justified.
When two items both qualify for delivery, the framework resolves the tie by favouring alignment with the current focus, lower delivery cost or faster outcome feedback -without introducing additional scoring.
The framework also acknowledges political reality. Some work is mandated. Such items are marked as Forced Deliver (Forced Deliver does not imply endorsement, only acknowledgement) outside the loop. They still require an intended effect and an outcome check, but bypass learning discussions. This keeps the framework honest without pretending that all decisions are optional.
Closing the loop
An item exits the Resonance Action Loop when its delivery outcome is confirmed, when an explicit no is final or when the underlying problem no longer exists. Habitual re-triage without new information is avoided.
Used consistently, the loop creates a shared decision language that connects thinking, action and learning.
Limitations by design
The Resonance Action Loop does not generate ideas, replace discovery or eliminate politics. It requires real decision authority and disciplined moderation. Where these conditions are absent, the framework will feel uncomfortable and that discomfort is often diagnostic.
Conclusion
The Resonance Action Loop is not about ranking work.
It is about deciding how to act and taking responsibility for the effect.
By making uncertainty explicit, separating evaluation from action and tying delivery to observable outcomes, the framework turns prioritisation from an abstract debate into a concrete learning system. This is not prioritisation as ranking, but capacity allocation through explicit decisions.
A decision without an action and an outcome check is not a decision. It is a delay.
That is the standard the Resonance Action Loop enforces and the reason it works.
The following section provides calibration heuristics and worked examples. For facilitation-ready formats, additional practice material is available, including a dedicated training slide deck, a workshop guide and a curated example library.
Evaluating decisions: examples and ranges that actually help
The Resonance Action Loop deliberately avoids precise scoring.
Still, teams need shared reference points. The following ranges and examples are heuristics, not rules. Their purpose is alignment, not accuracy.
Intended Effect - with concrete examples
Each decision must have one primary intended effect.
Reliability
Avoiding disappointment and broken expectations
Typical examples
Fixing login failures or data loss bugs
Improving performance where users already complain
Security, compliance, uptime, billing correctness
Typical smell
“Nobody complains yet, but this might break one day.”
→ Often not Reliability, but Load Reduction.
Usage Lift
Increasing meaningful usage or adoption
Typical examples
Improving onboarding completion
Reducing friction in a critical flow
Making a key feature easier to discover
Non-examples
Cosmetic UI changes without behavioural intent
“This would be nice” improvements
Heuristic check
“Would this measurably change how often or how deeply users use the product?”
Positioning
Signalling what the product stands for
Typical examples
Launching a flagship capability
Supporting a strategic integration or platform bet
Capabilities used in demos, sales narratives or announcements
Common mistake
Treating internal cleanup as Positioning because it feels important.
Positioning is outward-facing, even when internally motivated.
Load Reduction
Reducing friction, complexity or risk for users or the team
Typical examples
Paying down recurring tech debt
Removing manual operational steps
Simplifying configuration or workflows
Heuristic
“Would this make future work or usage consistently cheaper?”
Pull Strength: ranges with examples (1-5)
Pull Strength answers:
How painful would it be if we don’t act?
Pull Typical meaning Example
--------------------------------------------------------
1 Barely noticeable Minor UX polish
2 Mild irritation Known workaround exists
3 Clear annoyance Repeated support questions
4 Strong pain Drop-offs, escalations
5 Acute / urgent Revenue loss, trust damageInternal work note
For tech or platform items, Pull reflects:
accumulated risk
repeated friction
growing operational cost
Not “how much engineers want it”.
Evidence Level: what 0.5 / 1.0 / 1.5 actually mean
Evidence Level describes what the decision is based on, not how convinced someone feels.
Level Meaning Typical evidence
----------------------------------------------------
0.5 Assumption Opinions, intuition
1.0 Observed Logs, tickets, interviews
1.5 Proven Experiments, real behaviourExample
“Users drop off here” → 1.0
“We ran an A/B test and saw +8% completion” → 1.5
Important
Deliver with Evidence < 1.0 is allowed only with explicit risk acceptance.
Delivery Cost: anchoring the 1-5 range
Delivery Cost includes effort, risk and dependencies.
Each team defines its own anchor. A typical pattern:
Cost Rough meaning
----------------------------------------
1 Trivial / config change
2 Small change, few days
3 Typical delivery effort
4 Multi-sprint, dependencies
5 Large, risky, cross-teamRule of thumb
If teams argue about 2 vs 3, it’s probably a 3.
Precision here adds little value.
From evaluation to action - worked examples
Example 1: Login instability
Intended Effect: Reliability
Pull Strength: 5 (users locked out)
Evidence Level: 1.5 (error logs, tickets)
Delivery Cost: 2
→ Deliver
Outcome Check
Expected outcome: “Fewer login failures.”
Signal: error rate, support tickets
Observation window: 1 week
Example 2: AI-powered insights idea
Intended Effect: Positioning
Pull Strength: 3
Evidence Level: 0.5
Delivery Cost: 5
→ Learn
Learning question
“Do users actually trust and use AI insights?”
Smallest test
Prototype + interviews
Example 3: Refactor legacy export pipeline
Intended Effect: Load Reduction
Pull Strength: 4 (frequent incidents)
Evidence Level: 1.0
Delivery Cost: 4
→ Deliver (often justified despite invisibility)
Example 4: Feature request from one large customer
Intended Effect: Usage Lift
Pull Strength: 2
Evidence Level: 1.0
Delivery Cost: 3
→ Explicit No (Not worth it)
Reason:
High cost, limited systemic effect.
Learn vs Deliver: common boundary cases
Good candidates for Learn
Pull ≥ 3, Evidence ≤ 0.5
Delivery Cost ≥ 4 with unclear upside
Strategic ideas without behavioural proof
Good candidates for Deliver
Evidence ≥ 1.0 and Pull ≥ 3
Reliability items with clear risk
Load Reduction with recurring cost
Outcome Checks: realistic examples
Intended Effect Expected outcome Signal
-----------------------------------------------------------------
Reliability Fewer failed actions Error rate
Usage Lift More completed flows Funnel completion
Positioning Feature used in demos Sales feedback
Load Reduction Less manual work Ops time / incidentsReminder
Outcome signals indicate correlation.
If causality is unclear → Learn, not debate.
Decision Focus: example application
Quarter focus: Reliability
65% capacity → bug fixes, performance
20% → necessary Load Reduction
15% → forced or exceptional items
A Usage Lift feature may still ship, but it must justify breaking focus.
Why ranges matter (and why they are loose)
The purpose of ranges is not optimisation.
It is shared intuition.
If two teams score differently but decide the same action, the framework worked.
Final takeaway
The Resonance Action Loop becomes usable not through formulas, but through examples that calibrate judgement.
Once teams internalise these ranges, the framework fades into the background—and decisions become clearer, faster and more honest.
Good frameworks disappear in use.
Supporting materials
To support adoption and consistent use, the Resonance Action Loop is accompanied by three practical resources: a training slide deck that introduces the framework and its decision logic, a workshop guide that provides a step-by-step structure for facilitation and group decision-making and an example library that documents real and worked-through decisions for calibration and reference. These materials are designed to complement the framework, not replace it.